



The PDF format was originally developed as a way to store information while preserving the layout, so extracting data from PDF documents can be quite difficult. What is PDF Parser? Sometimes it called PDF scraper. It’s a software which can be used to extract data from PDF documents.
PDF parsers are used primarily to quickly extract data from PDF files. You can also manually extract data (copy and paste), but this is more time consuming and justified if you need to parse a couple of documents.
What kind of data can be parsed from PDF files?
PDF files are ideal for many different types of documents, from books, presentations, reports, brochures to court decisions, and purchase orders. In general, a PDF can be resource-rich because the standard allows almost any medium to be embedded in it.
Therefore, we can try to extract all this data back from the document. Typically, PDF parsers are used to extract paragraphs of text, tabular data (tables or lists), and images, less commonly for data fields, bookmarks, and attachments.
What are typical use-cases for a PDF Parsers / PDF Scraper?
These apps are used in various fields, ranging from document management, document indexing to business process automation with the goal of automatically extracting data from PDF files.
The possibility of successful parsing PDF files depends highly on the nature of documents and not all document types can be parsed.
How we can extract data using Aspose Free App
There are several applications that can be used to retrieve data.
Text extraction. In other words, it’s a conversion PDF to Text, and you can use PDF to TXT conversion for this purpose.
Table data. Obviously, tabular data is conveniently stored in a structured format like an Excel spreadsheet or CSV. We propose to use for that PDF to XLSX or PDF to CSV converters.
To make a complex extraction we propose to use a free Aspose.PDF Parser.
What can the Aspose.PDF Parser do?
- It allows handling 10 PDF documents at once;
- Extract text, images, attachments, bookmarks and form data
Aspose.PDF Parser uses a 1-click concept like other free web apps from Aspose. So, first, you need to upload the desired files and then press the Parse button.
As a result, you will receive a ZIP archive containing:
- a text file named as an original PDF document with extracted text;
- an images folder with all extracted images;
- an attachments folder with extracted attachments;
- bookmarks.xml file that stored bookmarks from the original document;
- annotations.xdf file with comments and other annotations from the document;
- formdata.xdf file with field data from the document;
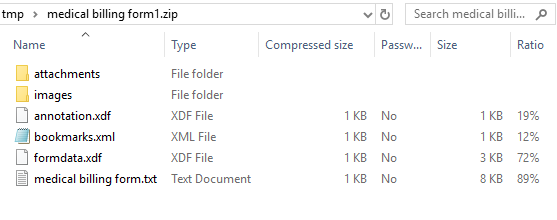
The last 3 files can be empty if the corresponding data types were not present in the original file.
Annotations and form data have been stored in FDF format, which is used as an interchange format between PDF documents.
For a better understanding of the parser, we also suggest watching a short video about how to extract images from the document.